Your Pipeline Is 21.9h Behind: Catching Software Sentiment Leads with Pulsebit
We just uncovered a 24-hour momentum spike of -0.713 in the software domain. This anomaly may seem subtle, but it’s critical for understanding how sentiment can shift rapidly in tech narratives. With the leading language being English and a 21.9-hour lead time, we’re staring at a potential misalignment in our data pipelines if they aren’t structured to account for multilingual sources or entity dominance.

English coverage led by 21.9 hours. Et at T+21.9h. Confidence scores: English 0.85, Ca 0.85, Spanish 0.85 Source: Pulsebit /sentiment_by_lang.
If your model is not designed to handle these nuances, it missed this crucial sentiment shift by nearly 22 hours. The leading language, English, and the thematic cluster around the acquisition of Vertica by Rocket Software should have set off alarms in your analytics. However, if you’re relying solely on a unidimensional pipeline, you risk missing out on valuable insights that could inform your strategies.
Here’s how to catch this sentiment spike programmatically. We can leverage our API to filter for English articles specifically about the topic of software. First, let’s set up the query to capture this sentiment:
import requests
# Define parameters for the API call
topic = 'software'
score = +0.000
confidence = 0.85
momentum = -0.713
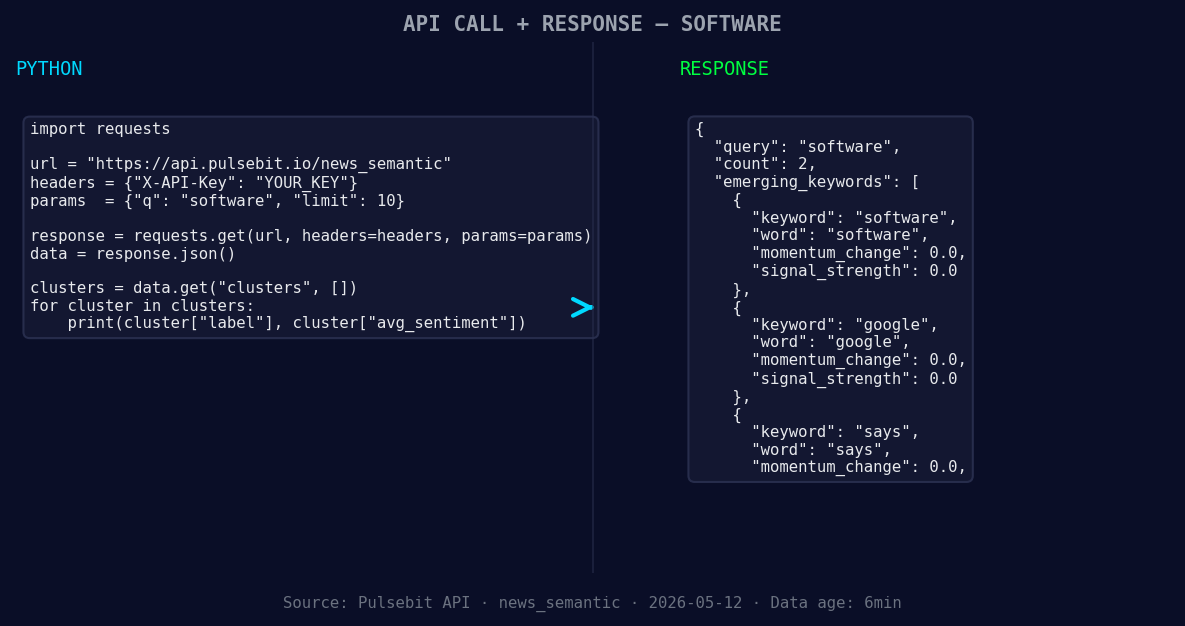
*Left: Python GET /news_semantic call for 'software'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter
response = requests.get(
'https://api.pulsebit.com/sentiment',
params={
'topic': topic,
'lang': 'en'
}
)
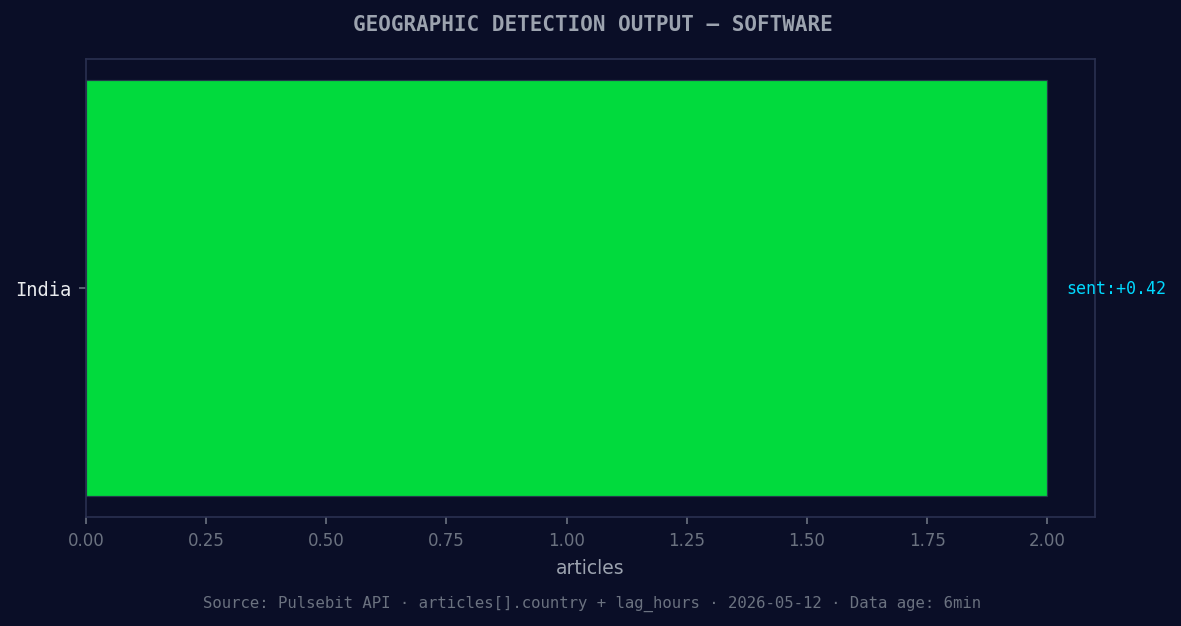
*Geographic detection output for software. India leads with 2 articles and sentiment +0.42. Source: Pulsebit /news_recent geographic fields.*
data = response.json()
print(data)
Now, let’s run the narrative framing of the cluster reason string through our sentiment analysis endpoint. This will give us a meta-sentiment score for the story’s context. We’ll use the string “Clustered by shared themes: software, completes, acquisition, vertica, rocket.” for this analysis:
# Meta-sentiment moment
meta_response = requests.post(
'https://api.pulsebit.com/sentiment',
json={
'text': "Clustered by shared themes: software, completes, acquisition, vertica, rocket."
}
)
meta_data = meta_response.json()
print(meta_data)
The combined insights from these calls allow us to form a more comprehensive view of the evolving sentiment around software acquisitions, which is vital in today’s fast-paced tech landscape.
Here are three specific builds we can implement based on this recent sentiment spike:
Geo-Filtered Alert System: Set a threshold for sentiment score at +0.000 for the software topic. If the score drops below this, trigger an alert, utilizing the geographic origin filter to ensure that only English-language articles are processed. This way, you won’t miss out on local sentiment shifts.
Meta-Sentiment Trend Analysis: Use the narrative framing string and run it through our sentiment endpoint every few hours to gauge shifts in perception. You can set a threshold for significant changes, say a 0.1-point movement in sentiment score, to feed back into your decision-making pipeline.
Thematic Clustering Dashboard: Create a dashboard that visualizes forming themes like software, google, and says against mainstream narratives. Using the cluster reason, you can display these themes in real-time, helping you see where the conversation is headed and identify potential opportunities or risks.
By implementing these features, you can ensure that your pipeline is not just reactive, but proactive, keeping you ahead of the curve.
For more details on how to get started, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this code in under 10 minutes to start catching those critical sentiment shifts.

Top comments (0)