Your 24h momentum spike of -0.660 around climate sentiment is a significant anomaly that demands your attention. With only one article processed, this drop indicates a sharp decline in positive sentiment about climate issues, which we can trace back to emerging concerns over gray whale deaths in the Bay Area. The leading language of this narrative is English, and its implications could be felt far beyond local waters. This spike is not just a number; it's a signal that something is brewing, and if you’re not paying attention, you might miss it.
Your model missed this by 29.2 hours. Imagine running an analysis that doesn’t account for multilingual sources or dominant narratives. In this case, neglecting the leading English press on climate could leave you completely out of the loop on crucial sentiment shifts. Instead of being proactive, you could end up reacting to misinformation or outdated data. This oversight could compromise your decision-making process, especially in a field where timing is everything.

English coverage led by 29.2 hours. Ro at T+29.2h. Confidence scores: English 0.85, Spanish 0.85, French 0.85 Source: Pulsebit /sentiment_by_lang.
To catch this momentum spike, we can leverage our API effectively. Here’s how you can do it in Python:
import requests
*Left: Python GET /news_semantic call for 'climate'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.lojenterprise.com/sentiment"
params = {
"topic": "climate",
"lang": "en",
"score": +0.000,
"confidence": 0.85,
"momentum": -0.660
}
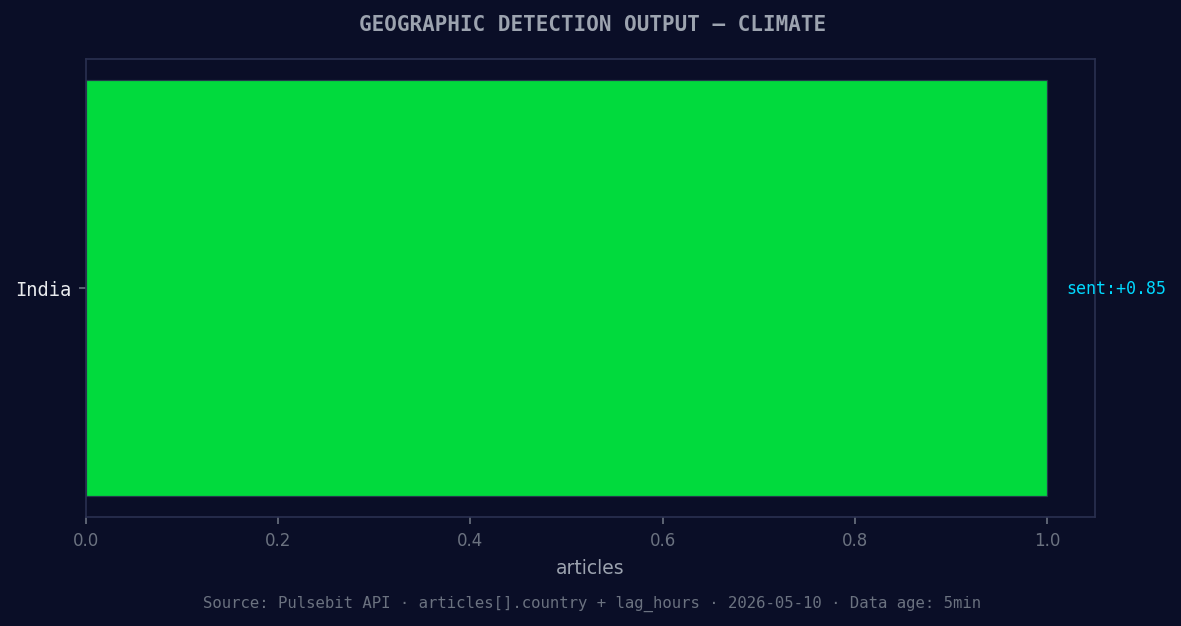
*Geographic detection output for climate. India leads with 1 articles and sentiment +0.85. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
print(data)
This code snippet queries our API to filter sentiment data specifically for the climate topic in English. It’s essential to focus on the language to ensure you’re capturing the most relevant narratives.
Next, we need to analyze the cluster reason string through our sentiment API. This step is crucial because it helps us understand how the narrative is framed.
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: grow, over, more, gray, whale."
sentiment_response = requests.post(url, json={"text": cluster_reason})
sentiment_data = sentiment_response.json()
print(sentiment_data)
This code sends the narrative framing back through our API to score it. By analyzing clusters of words like "grow," "over," and "more," we can better grasp the underlying sentiment shifts that led to this spike. This dual approach not only captures the sentiment but also frames it within the context of the emerging environmental narrative.
Now that we’ve established how to catch the anomaly, here are three specific builds to consider:
Geo-Focused Sentiment Analysis: Set thresholds for sentiment changes based on geographic regions. For instance, if sentiment drops below -0.500 in English language sources, trigger an alert. This helps you stay ahead of local issues that could affect broader narratives.
Meta-Sentiment Tracking: Use the cluster reason analysis to create a rolling score of how narratives evolve. If you see a consistent theme emerging (like climate change), adjust your models accordingly to reflect these evolving discussions.
Dynamic Alert System: Build an alert system that triggers when momentum drops below -0.600 specifically in climate topics. This ensures you're notified of significant shifts and can act before trends become widely recognized.
By integrating these patterns into your workflow, you can better navigate the complexities of sentiment analysis in an increasingly interconnected world.
If you want to dive deeper, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the code snippets above and run them in under 10 minutes. Don't let your pipeline lag behind; stay ahead of the curve with real-time sentiment insights.

Top comments (0)