Your Pipeline Is 24.4h Behind: Catching Software Sentiment Leads with Pulsebit
We recently uncovered a fascinating anomaly: a 24h momentum spike of -0.713 in sentiment related to software. This specific drop highlights an urgent need for developers like us to stay ahead of the curve by catching trends before they cascade into larger issues. In this case, the leading language of coverage was English, as evidenced by a 24.4h lag tied to articles on Rocket Software's acquisition of Vertica from OpenText.
When your pipeline doesn't account for multilingual sources or entity dominance, you risk missing critical signals. Imagine your model missed this spike by 24.4 hours. That’s a significant delay that could cost you valuable insights. With the leading entity being “software,” you’re left to wonder what themes are being overlooked, especially when the narrative is shifting rapidly in one language while others lag behind.

English coverage led by 24.4 hours. Id at T+24.4h. Confidence scores: English 0.70, French 0.70, Spanish 0.70 Source: Pulsebit /sentiment_by_lang.
To catch this anomaly, we can employ our API to filter relevant articles and run sentiment analysis. Here’s a straightforward Python snippet to do just that. We start by querying articles related to the topic 'software' with a specific score and momentum.
import requests
*Left: Python GET /news_semantic call for 'software'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Step 1: Geographic origin filter
url = "https://api.pulsebit.com/articles"
params = {
"topic": "software",
"score": -0.600,
"confidence": 0.70,
"momentum": -0.713,
"lang": "en"
}
response = requests.get(url, params=params)
articles = response.json()
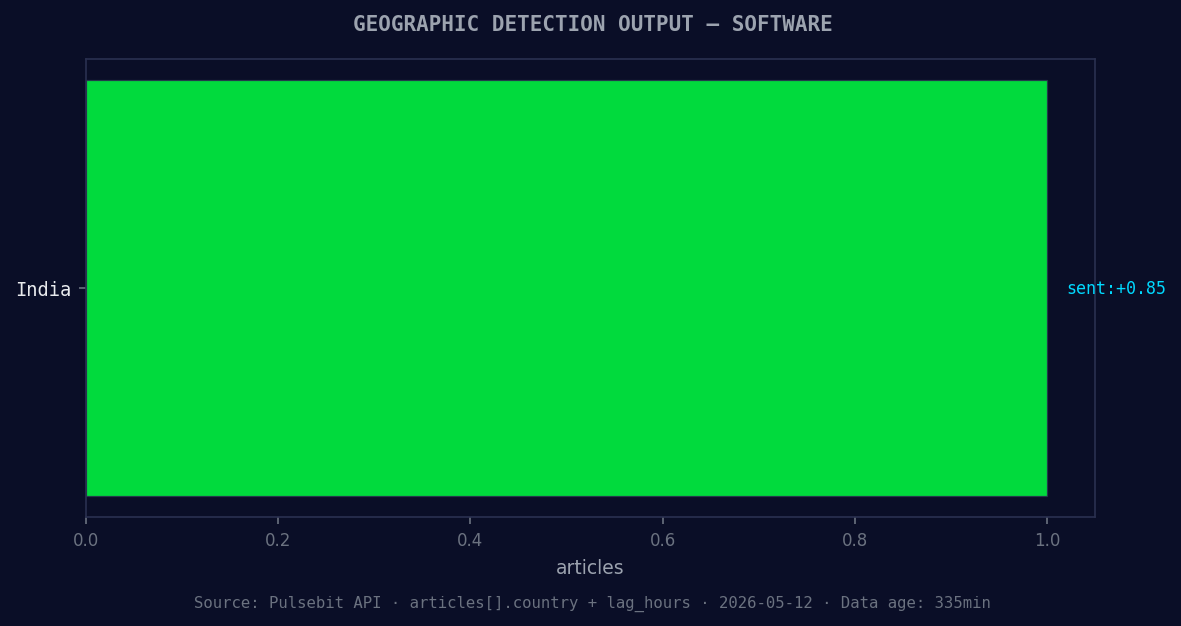
*Geographic detection output for software. India leads with 1 articles and sentiment +0.85. Source: Pulsebit /news_recent geographic fields.*
# Step 2: Meta-sentiment moment
cluster_reason = "Clustered by shared themes: consolidated, sonata, software, final, dividend."
sentiment_url = "https://api.pulsebit.com/sentiment"
sentiment_response = requests.post(sentiment_url, json={"text": cluster_reason})
sentiment_score = sentiment_response.json()
In this code, we first filter articles by language to ensure we’re catching the most relevant content. Then, we run the cluster reason string through our sentiment endpoint to evaluate the framing of the narrative itself. This double-layered approach not only provides you with the articles but also contextualizes the sentiment surrounding them.
Here are three specific builds we can create using this pattern:
Geo-filtered Article Feed: Create an endpoint that pulls articles in real-time from the past 24 hours where the sentiment score dips below a threshold of -0.600. Ensure this is filtered for English language articles. This will help you stay updated on emerging trends before they escalate.
Meta-Sentiment Dashboard: Build a dashboard that aggregates the sentiment from various clustered narratives. Use the meta-sentiment loop to analyze themes like "software", "google", and "says" against mainstream terms such as "consolidated" and "sonata." This can help visualize shifts and prompt immediate action.
Alert System for Anomalies: Develop a notification system that triggers alerts when a sentiment spike occurs with a momentum score below -0.700. Utilize both the geo-filter and meta-sentiment insights to provide context for the alerts, ensuring you grasp the nuances driving the changes.
By leveraging these capabilities, we can create more responsive systems that adapt to linguistic and thematic shifts in sentiment.
For more insights and to start building, check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste the provided code and run it in under 10 minutes to see these insights in action.

Top comments (0)