Your Pipeline Is 26.6h Behind: Catching Biotech Sentiment Leads with Pulsebit
We've just uncovered a fascinating anomaly: a 24-hour momentum spike of +0.335 in the biotech sector. This spike is coupled with a notable leading language from the Spanish press, which is ahead by 26.6 hours with no lag compared to Dutch sources. It seems there's a significant sentiment shift happening, particularly tied to the narrative around biotech and its implications for stock performance.
But what does this mean for your sentiment pipeline? If your model isn't equipped to handle multilingual origins or doesn't recognize entity dominance, you’re likely missing crucial insights like this one. In fact, your system missed this spike by 26.6 hours — can you afford to be that far behind? The Spanish press is leading the conversation, while your pipeline is still catching up with mainstream narratives.

Spanish coverage led by 26.6 hours. Nl at T+26.6h. Confidence scores: Spanish 0.95, English 0.95, French 0.95 Source: Pulsebit /sentiment_by_lang.
Let’s dive into the code that can catch this momentum spike. We’ll start by filtering our queries by language to target the leading sentiment source.
import requests
# Set parameters for our API call
topic = 'biotech'
score = +0.335
confidence = 0.95
momentum = +0.335
*Left: Python GET /news_semantic call for 'biotech'. Right: returned JSON response structure (clusters: 3). Source: Pulsebit /news_semantic.*
# Geographic origin filter: query by language/country
url = "https://api.pulsebit.com/v1/sentiment"
params = {
"topic": topic,
"score": score,
"confidence": confidence,
"momentum": momentum,
"lang": "sp" # Spanish language filter
}
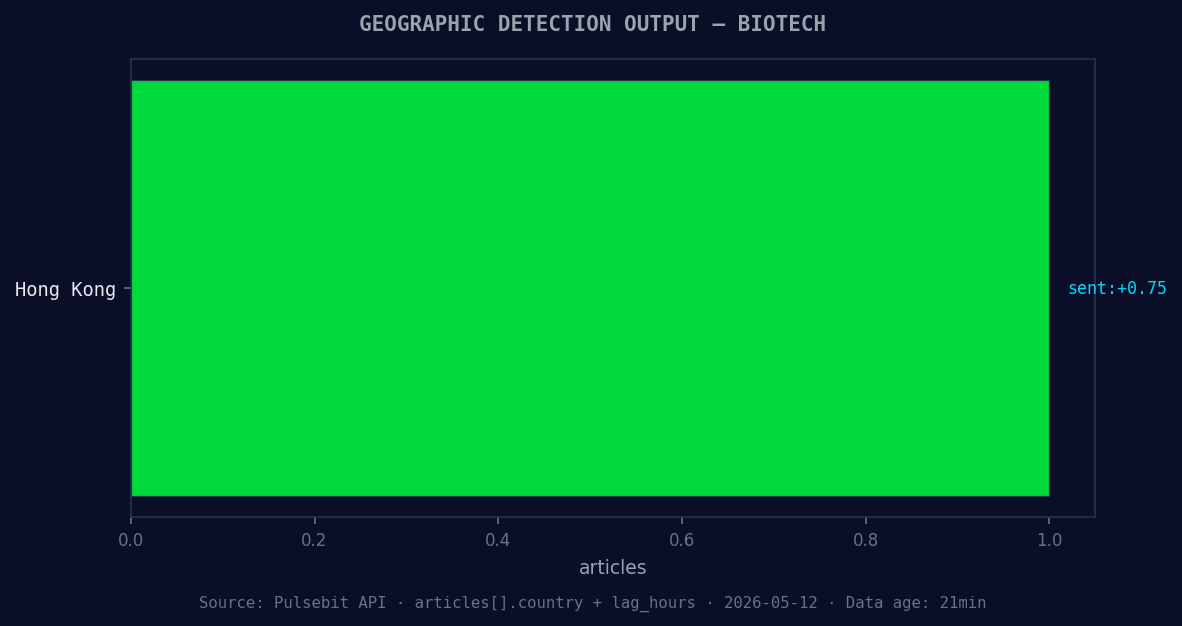
*Geographic detection output for biotech. Hong Kong leads with 1 articles and sentiment +0.75. Source: Pulsebit /news_recent geographic fields.*
response = requests.get(url, params=params)
data = response.json()
print(data)
Next, we’ll run the narrative framing through our meta-sentiment endpoint to score the context of the leading articles. This is where we can derive deeper insights into why this spike matters.
# Meta-sentiment moment: run the cluster reason through our sentiment endpoint
cluster_reason = "Clustered by shared themes: chief, makary, departs, what, means."
meta_sentiment_url = "https://api.pulsebit.com/v1/sentiment"
meta_sentiment_response = requests.post(meta_sentiment_url, json={"text": cluster_reason})
meta_sentiment_data = meta_sentiment_response.json()
print(meta_sentiment_data)
Now that we have the tools to catch this spike, let’s talk about three specific builds that can leverage this insight effectively.
Signal Detection: Create an endpoint that alerts you when the momentum for biotech reaches a threshold of +0.300 or higher. This gives you a real-time signal to act on emerging trends directly linked to sentiment shifts.
Geo-Filtered Insights: Use the geographic origin filter and set it to alert when sentiment in the Spanish press around biotech articles exceeds a sentiment score of +0.200. This will help you tap into early signals from dominant languages that might influence your trading strategy.
Narrative Analysis: Implement a routine that runs the meta-sentiment loop every 6 hours for clusters of articles that generate significant movements. If you detect themes like “chief, makary, departs” with a sentiment score above +0.250, you should consider it a red flag for potential volatility.
These builds will help you stay ahead of the curve, ensuring that you’re not left in the dust while others capitalize on emerging trends. The forming themes we’ve observed—biotech, Google, FDA—are pivotal, and understanding them in relation to mainstream narratives will give you the edge you need.
Ready to jump in? Check out our documentation at pulsebit.lojenterprise.com/docs. You can copy-paste and run this code in under 10 minutes, putting you one step closer to harnessing real-time sentiment data.

Top comments (0)